For the past several weeks, I’ve been thinking about computer code and language as a means of control. For Alexander Galloway, code is a type of protocol, or a way of imposing control in communication. In Protocol, Galloway describes code as a language (yet to be officially recognized as such) that requires adherence to its standards in order to work. For Kenneth Goldsmith, code offers an opportunity to be creative. In Uncreative Writing, Goldsmith talks about remixing different kinds of “code,” such as the code from an image file with lines of poetry, to create a new image. I’m wondering how we can bring what Galloway says about control and restraint in code into conversation with Goldsmith’s presentation of creative uses of code.
Galloway shows how power structures, such as DNS and ISP, are instituted through code, which must conform to a certain standard in order to successfully communicate. For Galloway, resistance to this kind of control consists of finding loopholes or “exploits” in systems (what hackers do). But Goldsmith shows how resistance to standards can take a different route, how it can actually defy the requirements of protocol, by splicing the standard code with other kinds of code, or languages. This remixing is creative because it combines two different codes (such as poetry and computer code) to create something new.
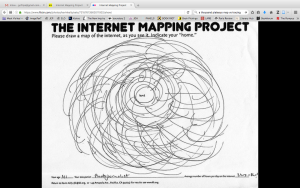
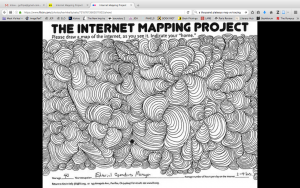
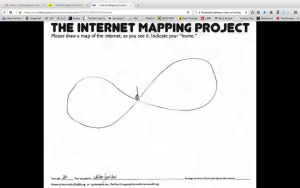
On page 24 in Uncreative Writing. Goldsmith performs an experiment with an image of William Shakespeare. His experiment takes the textual code from the image and splices it with the text from a Shakespearean sonnet. The resulting .jpg file renders a jumbled image. I performed the same experiment with a picture of my family’s thanksgiving table. Here, I took the code from a .jpg file and spliced it with text (in this case, with an argument that my family had at the table when the picture was taken). The result looks like this:

The image shows two things: first, how the code doesn’t work, and second, how this failure nonetheless results in an image that is read and rendered by the computer. In this case, the remixing of code is both corruptive and creative. It shows that mixing different kinds of languages, such as English and computer code, successfully resists standards.
I realize that Galloway’s project is ultimately about communication, while Goldsmith’s is about creating something new from old materials. But it seems to me that we can see the two in the same light, as a resistance to the control of language through experimentation. Do you think this experiment changes how we view protocol? Is mixing different kinds of code analogous to Galloway’s “exploit”, or is it something else?